编辑:李子吉
审核:艾丽
政审:王军善


中国战略新兴产业融媒体记者 李子吉
神经形态计算是一种新型计算机架构,其中计算机被构建为像人脑一样处理信息并与世界交互。具体来说,是将训练和推理整合到一起、将内存与计算能力集成于一体,使用神经网络构建机器,并通过物理方式实现信息的传递,从而模拟人脑神经元和突触进行运算。
据新华社消息,英特尔公司日前发布名为Hala Point的大型神经拟态系统,旨在支持类脑人工智能领域的前沿研究,解决人工智能在效率和可持续性等方面的挑战。
根据英特尔公司发表的新闻公报,英特尔在其第一代大规模研究系统Pohoiki Springs的基础上,改进了Hala Point大型神经拟态系统的架构,将神经元容量提高了10倍以上,性能提高了12倍。

以目前研究来看,生物大脑中,神经元细胞会通过树突、突触等实现信号传递与调整等功能,同时,神经元间会以脉冲信号形式相互交流。实际上,单个神经元的结构和功能并不复杂,但通过突触互连的大规模神经网络,就能实现各种复杂的学习和认知功能。
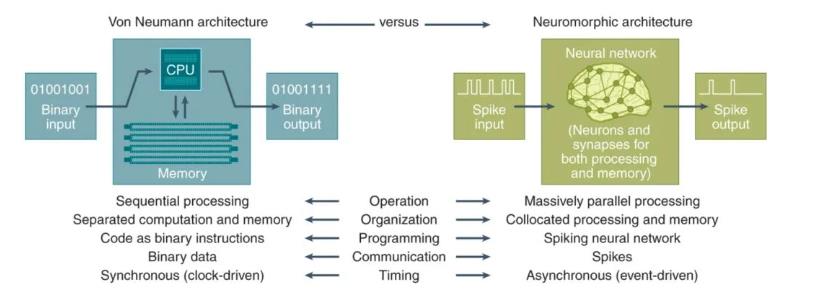
神经形态计算的创新架构方法将为未来需要能源效率和持续学习的自主人工智能解决方案提供动力。它有望在计算领域开创令人振奋的全新可能性,且已在各种领域中广泛应用,包括感应、机器人、医疗保健和大型人工智能应用程序。
END
编辑:李子吉
审核:艾丽
政审:王军善
终审:朱永旗
